Unity が勝手にシェーダーコードを書き換える?!
こんにちは、バーチャルキャストクライアント開発者の t-kuhn です。

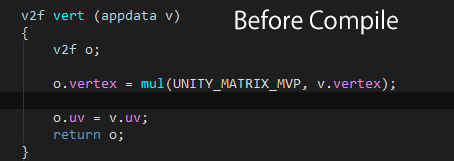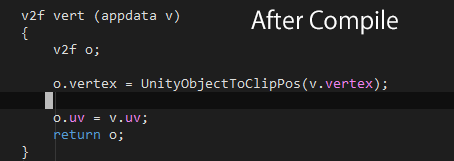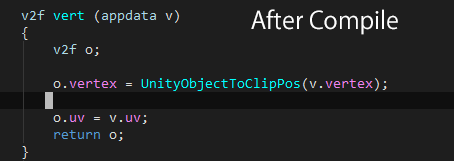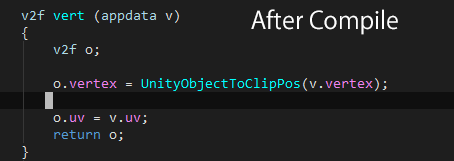
上図のように Unity がコンパイル時に勝手にシェーダーコードを書き換えることがあることはご存知でしたか?「何で書き換えるんだろう?」と気になって書き換える理由について調べました。
コードの確認
まず、コンパイル時に上書きされる箇所を確認しよう。
|
1 2 3 4 5 6 7 8 9 |
v2f vert (appdata v) { v2f o; o.vertex = mul(UNITY_MATRIX_MVP, v.vertex); // ← ここです o.uv = v.uv; return o; } |
vertex shader の中の
mul(UNITY_MATRIX_MVP, v.vertex) が UnityObjectToClipPos(v.vertex) に書き換えられます。
「そもそもこのコード、何をするコードなの?書き換えられる前と後とでやってる処理は一緒なの?」と疑問を持っている方もいるかもしれない。ここで一度それぞれの処理内容について確認しよう。
mul(UNITY_MATRIX_MVP, v.vertex)
まずは mul(UNITY_MATRIX_MVP, v.vertex)。
mul(x, y)は行列 x, y の掛け算をしてくれる関数。UNITY_MATRIX_MVPは現在の model view projection 行列。v.vertexは vertex shader に渡された頂点。
Q: で、結局何のための処理?
A: vertex shader のメインのお仕事はインプットされる model space の頂点位置を clip space に変換する処理です。

図1
しかし、実際の処理として様々なパターンが考えられます。ルート A で行くと
- 頂点位置をまず wold space に変換する
- 次に view space に変換する
- 最後に clip space に変換する
という流れになります。
一方、ルート B ではそれぞれの変換行列(model matrix, view matrix, projection matrix)をかけ合わせることによって直接に model space から clip space へと変換する行列(MVP matrix)を作成しておき、model space の頂点位置をこの行列にかけることで clip space への変換を行います。
mul(UNITY_MATRIX_MVP, v.vertex) のやっている処理はルート B に該当する処理です。
UnityObjectToClipPos(v.vertex)
Q: じゃあ、UnityObjectToClipPos(v.vertex) はどう違う?
A: UnityShaderUtilities.cginc で UnityObjectToClipPos() の定義を確認しよう。
|
1 2 3 4 5 6 7 8 9 10 |
// Tranforms position from object to homogenous space inline float4 UnityObjectToClipPos(in float3 pos) { #if defined(STEREO_CUBEMAP_RENDER_ON) return UnityObjectToClipPosODS(pos); #else // More efficient than computing M*VP matrix product return mul(UNITY_MATRIX_VP, mul(unity_ObjectToWorld, float4(pos, 1.0))); #endif } |
コンパイル時に UnityObjectToClipPos(pos) が mul(UNITY_MATRIX_VP, mul(unity_ObjectToWorld, float4(pos, 1.0))) に置き換えられますね。これで UnityObjectToClipPos(pos) の正体が分かった。しかし、図1でいうルート A でもルート B でもないということに注目してほしい。

図2
UnityObjectToClipPos(v.vertex) の処理は図2上のルート C です。一旦頂点位置を world space に変換してから UNITY_MATRIX_VPを用いて clip space に変換します。
理由について調べる
ここまで来てやっと置き換えられる理由についての話しになります。実は既にヒントが出ていました。UnityObjectToClipPos(pos) の定義のコードに着目してほしい。
|
1 2 3 4 5 6 7 8 9 10 |
// Tranforms position from object to homogenous space inline float4 UnityObjectToClipPos(in float3 pos) { #if defined(STEREO_CUBEMAP_RENDER_ON) return UnityObjectToClipPosODS(pos); #else // More efficient than computing M*VP matrix product return mul(UNITY_MATRIX_VP, mul(unity_ObjectToWorld, float4(pos, 1.0))); #endif } |
// More efficient than computing M*VP matrix product というコメントが書いてあります。これが置き換えられる理由です。
理由の確認
Q: more efficient(効率的) って言われても満足できない。具体的にどこが more efficient だろう?
A: それぞれの場合、実際にどんな計算が行われるかを見ていくと分かります。
mul(UNITY_MATRIX_MVP, v.vertex)を使ったときの計算量を確認
まずは mul(UNITY_MATRIX_MVP, v.vertex) です。 UnityShaderVariables.cginc でUNITY_MATRIX_MVP の define を確認すると
|
1 2 |
static float4x4 unity_MatrixMVP = mul(unity_MatrixVP, unity_ObjectToWorld); #define UNITY_MATRIX_MVP unity_MatrixMVP |
UNITY_MATRIX_MVP がコンパイル時に mul(unity_MatrixVP, unity_ObjectToWorld) に置き換えられることが分かる。よって、実際に行われる計算にこれも含めなければなりません。
まずは $\boldsymbol{M}_{\tiny{MVP}}$ を計算しなければならない。ここで、 $\boldsymbol{M}_{\tiny{M}}$ が model space → world space の変換行列、$\boldsymbol{M}_{\tiny{VP}}$ が world space → clip space の変換行列だとする。
$$
\begin{align}
\boldsymbol{M}_{\tiny{MVP}} = \boldsymbol{M}_{\tiny{VP}} \boldsymbol{M}_{\tiny{M}}
\tag{1.0}
\end{align}
$$
次に (1.0) で求まった $\boldsymbol{M}_{\tiny{MVP}}$ を用いて model space の頂点位置 $\boldsymbol{P}_{model}$ を clip space の頂点位置 $\boldsymbol{P}_{clip}$ に変換します。
$$
\begin{align}
\boldsymbol{P}_{clip} = \boldsymbol{M}_{\tiny{MVP}} \boldsymbol{P}_{model}
\tag{1.1}
\end{align}
$$
計算量を見てみると
- (1.0) 行列*行列
- (1.1) 行列*ベクトル
となります。
UnityObjectToClipPos(pos)を使ったときの計算量を確認
次は UnityObjectToClipPos(pos) の正体が
mul(UNITY_MATRIX_VP, mul(unity_ObjectToWorld, float4(pos, 1.0))) であることを思い出して、こちらの計算量を見てみよう。
mul(unity_ObjectToWorld, float4(pos, 1.0) を数学的に表現すると
$$
\begin{align}
\boldsymbol{P}_{world} = \boldsymbol{M}_{\tiny{M}} \boldsymbol{P}_{model}
\tag{2.0}
\end{align}
$$
と書けます。次に UNITY_MATRIX_VP に (2.0) で得られたベクトルをかけるから
$$
\begin{align}
\boldsymbol{P}_{clip} = \boldsymbol{M}_{\tiny{VP}} \boldsymbol{P}_{world}
\tag{2.1}
\end{align}
$$
になります。計算量は以下の通りです。
- (2.0) 行列*ベクトル
- (2.1) 行列*ベクトル
結論
上記の計算量のデータを比較すると // More efficient than computing M*VP matrix product の more efficient の理由が分かります。つまり、
行列*ベクトル + 行列*ベクトルの計算量 < 行列*行列 + 行列*ベクトルの計算量
ということですね。Unity が勝手にシェーダーコードを上書きする理由が「計算量を減らし、パフォーマンスをより良くしたい」でした!
- Tag
- Unity